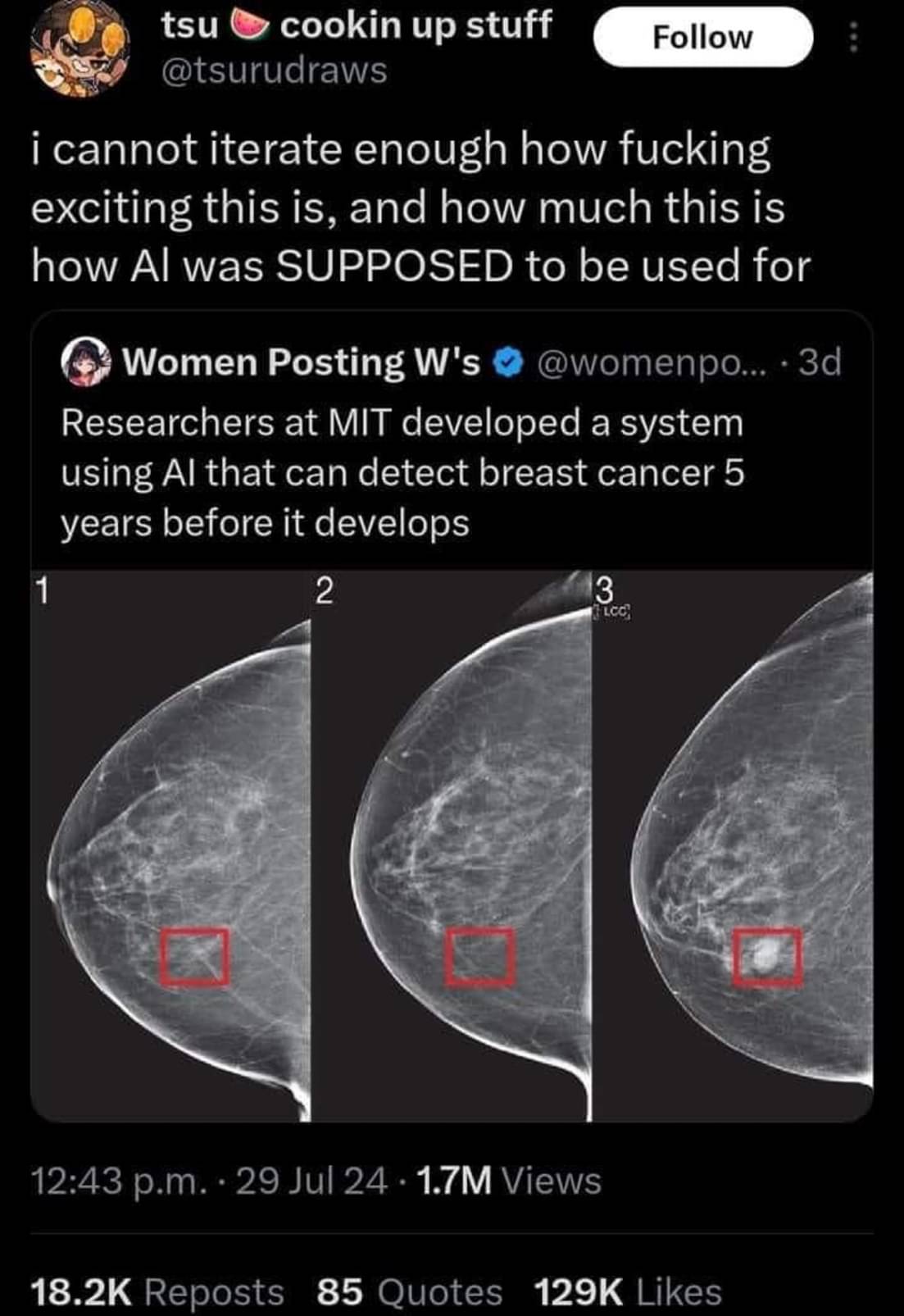
The thing is tho… It has a better detection rate ON THE SAMPLES THEY HAD but because it wasn’t actually detecting anything other than wealth there was no way for them to trust it would stay accurate.
Right, there’s typically separate “training” and “validation” sets for a model to train, validate, and iterate on, and then a totally separate “test” dataset that measures how effective the model is on similar data that it wasn’t trained on.
If the model gets good results on the validation dataset but less good on the test dataset, that typically means that it’s “over fit”. Essentially the model started memorizing frivolous details specific to the validation set that while they do improve evaluation results on that specific dataset, they do nothing or even hurt the results for the testing and other datasets that weren’t a part of training. Basically, the model failed to abstract what it’s supposed to detect, only managing good results in validation through brute memorization.
I’m not sure if that’s quite what’s happening in maven’s description though. If it’s real my initial thoughts are an unrepresentative dataset + failing to reach high accuracy to begin with. I buy that there’s a correlation between machine specs and positive cases, but I’m sure it’s not a perfect correlation. Like maven said, old areas get new machines sometimes. If the models accuracy was never high to begin with, that correlation may just be the models best guess. Even though I’m sure that it would always take machine specs into account as long as they’re part of the dataset, if actual symptoms correlate more strongly to positive diagnoses than machine specs do, then I’d expect the model to evaluate primarily on symptoms, and thus be more accurate. Sorry this got longer than I wanted
It’s no problem to have a longer description if you want to get nuance. I think that’s a good description and fair assumptions. Reality is rarely as black and white as reddit/lemmy wants it to be.
What if one of those lower economic areas decides that the machine is too old and they need to replace it with a brand new one? Now every single case is a false negative because of how highly that was rated in the system.
The data they had collected followed that trend but there is no way to think that it’ll last forever or remain consistent because it isn’t about the person it’s just about class.


{kind=link}
The thing is tho… It has a better detection rate ON THE SAMPLES THEY HAD but because it wasn’t actually detecting anything other than wealth there was no way for them to trust it would stay accurate.
Citation needed.
Usually detection rates are given on a new set of samples, on the samples they used for training detection rate would be 100% by definition.
Right, there’s typically separate “training” and “validation” sets for a model to train, validate, and iterate on, and then a totally separate “test” dataset that measures how effective the model is on similar data that it wasn’t trained on.
If the model gets good results on the validation dataset but less good on the test dataset, that typically means that it’s “over fit”. Essentially the model started memorizing frivolous details specific to the validation set that while they do improve evaluation results on that specific dataset, they do nothing or even hurt the results for the testing and other datasets that weren’t a part of training. Basically, the model failed to abstract what it’s supposed to detect, only managing good results in validation through brute memorization.
I’m not sure if that’s quite what’s happening in maven’s description though. If it’s real my initial thoughts are an unrepresentative dataset + failing to reach high accuracy to begin with. I buy that there’s a correlation between machine specs and positive cases, but I’m sure it’s not a perfect correlation. Like maven said, old areas get new machines sometimes. If the models accuracy was never high to begin with, that correlation may just be the models best guess. Even though I’m sure that it would always take machine specs into account as long as they’re part of the dataset, if actual symptoms correlate more strongly to positive diagnoses than machine specs do, then I’d expect the model to evaluate primarily on symptoms, and thus be more accurate. Sorry this got longer than I wanted
It’s no problem to have a longer description if you want to get nuance. I think that’s a good description and fair assumptions. Reality is rarely as black and white as reddit/lemmy wants it to be.
What if one of those lower economic areas decides that the machine is too old and they need to replace it with a brand new one? Now every single case is a false negative because of how highly that was rated in the system.
The data they had collected followed that trend but there is no way to think that it’ll last forever or remain consistent because it isn’t about the person it’s just about class.
The goalpost has been moved so far I now need binoculars to see it now