

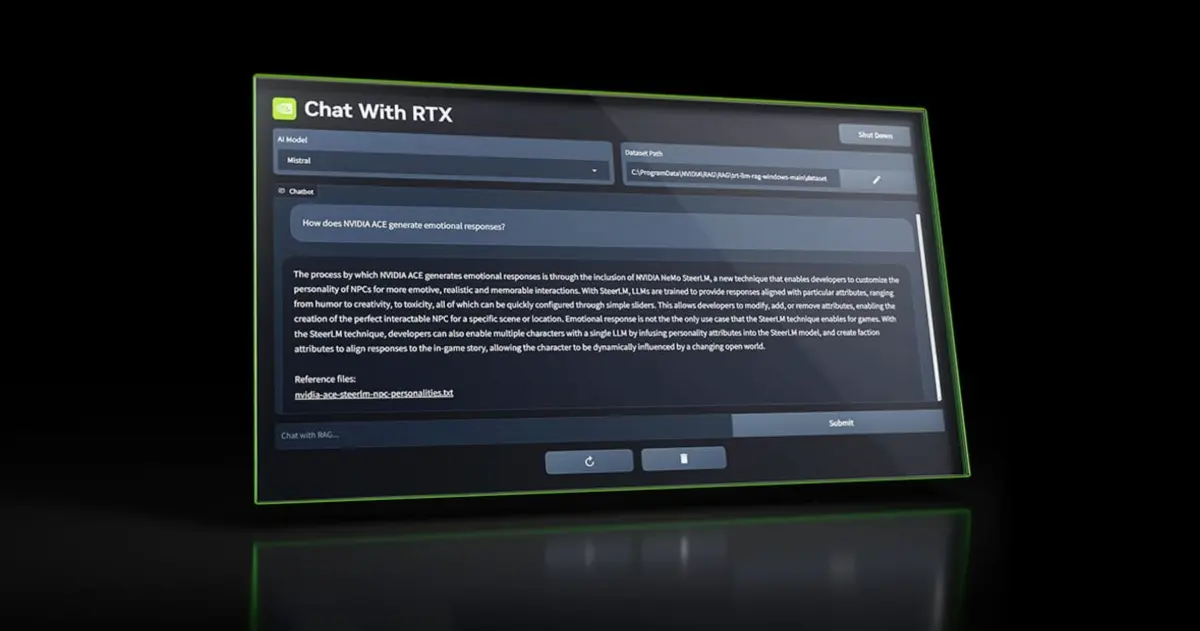
• NVIDIA released a demo version of a chatbot that runs locally on your PC, giving it access to your files and documents.
• The chatbot, called Chat with RTX, can answer queries and create summaries based on personal data fed into it.
• It supports various file formats and can integrate YouTube videos for contextual queries, making it useful for data research and analysis.
That was an annoying read. It doesn’t say what this actually is.
It’s not a new LLM. Chat with RTX is specifically software to do inference (=use LLMs) at home, while using the hardware acceleration of RTX cards. There are several projects that do this, though they might not be quite as optimized for NVIDIA’s hardware.
Go directly to NVIDIA to avoid the clickbait.
Chat with RTX uses retrieval-augmented generation (RAG), NVIDIA TensorRT-LLM software and NVIDIA RTX acceleration to bring generative AI capabilities to local, GeForce-powered Windows PCs. Users can quickly, easily connect local files on a PC as a dataset to an open-source large language model like Mistral or Llama 2, enabling queries for quick, contextually relevant answers.
Source: https://blogs.nvidia.com/blog/chat-with-rtx-available-now/
Download page: https://www.nvidia.com/en-us/ai-on-rtx/chat-with-rtx-generative-ai/
Pretty much every LLM you can download already has CUDA support via PyTorch.
However, some of the easier to use frontends don’t use GPU acceleration because it’s a bit of a pain to configure across a wide range of hardware models and driver versions. IIRC GPT4All does not use GPU acceleration yet (might need outdated; I haven’t checked in a while).
If this makes local LLMs more accessible to people who are not familiar with setting up a CUDA development environment or Python venvs, that’s great news.
I’d hope that this uses the hardware better than Pytorch. Otherwise, why the specific hardware demands? Well, it can always be marketing.
There are several alternatives that offer 1-click installers. EG in this thread:
AGPL-3.0 license: https://jan.ai/
MIT license: https://ollama.com/
MIT license: https://gpt4all.io/index.html
(There’s more.)
Ollama with Ollama WebUI is the best combo from my experience.
Gpt4all somehow uses Gpu acceleration on my rx 6600xt
Ooh nice. Looking at the change logs, looks like they added Vulkan acceleration back in September. Probably not as good as CUDA/Metal on supported hardware though.
getting around 44 iterations/s (or whatever that means) on my gpu
i have no need to talk to my gpu, i have a shrink for that
Idk I kinda like the idea of a madman living in my graphics card. I want to be able to spin them up and have them tell me lies that sound plausible and hallucinate things.
Gpu is cheaper (somehow)
Your shrink renders video frames?
it gives the chatbot access to your files and documents
I’m sure nvidia will be trustworthy and responsible with this
They say it works without an internet connection, and if that’s true this could be pretty awesome. I’m always skeptical about interacting with chatbots that run in the cloud, but if I can put this behind a firewall so I know there’s no telemetry, I’m on board.
You can already do this. There are plenty of vids that show you how and it’s pretty easy to get started. Expanding functionality to get it to act and respond how you want is a bit more challenging. But definitely doable.
I recommend jan.ai over this, last I heard it mentioned it was a decent option.
I use https://huggingface.co/chat , you can also easily host open source models on your local machine
There’s also GPT4All that I’m aware of.
Or ollama.ai
The performance on my 3070 was awful, tools like LM Studio work significantly better.
Oh nooo, what an unfortunate turn of events. Guess that just means your GPU is too weak and old. How about upgrading to 40 series?
– Nvidia, probably
On my 4090, the performance is much better than ChatGPT4. The output is way worse though.
Yeah my boss did a screen share with me and it was done instantly, while mine was needing to recompile the embeddings for the 5th time
Shame they leave GTX owners out in the cold again.
2xxx too. It’s only available for 3xxx and up.
The whole point of the project was to use the Tensor cores. There are a ton of other implementations for regular GPU acceleration.
Just use Ollama with Ollama WebUI
deleted by creator
There were CUDA cores before RTX. I can run LLMs on my CPU just fine.
There are a number of local AI LLMs that run on any modern CPU. No GPU needed at all, let alone RTX.
This statement is so wrong. I have Ollama with llama2 dataset running decently on a 970 card. Is it super fast? No. Is it usable? Yes absolutely.
Source?
AI is a data harvesting free-for-all
Can I sing the NVIDIA song with it?
I had almost forgotten that existed
Thanks
Here is an alternative Piped link(s):
Piped is a privacy-respecting open-source alternative frontend to YouTube.
I’m open-source; check me out at GitHub.
I’m a bit of a noob here. Can someone please give me a few examples how I would use this on my local machine?










